一、理论部分
SKNet 针对卷积核的注意力机制 研究。
不同大小的感受视野(卷积核)对于不同尺度(远近、大小)的目标会有不同的效果。尽管比如 Inception 这样的增加了多个卷积核来适应不同尺度图像,但是一旦训练完成后,参数就固定了,这样多尺度信息就会被全部使用了(每个卷积核的权重相同)
SKNet 提出了一种机制,即 卷积核的重要性 —— 不同的图像能够得到具有不同重要性的卷积核
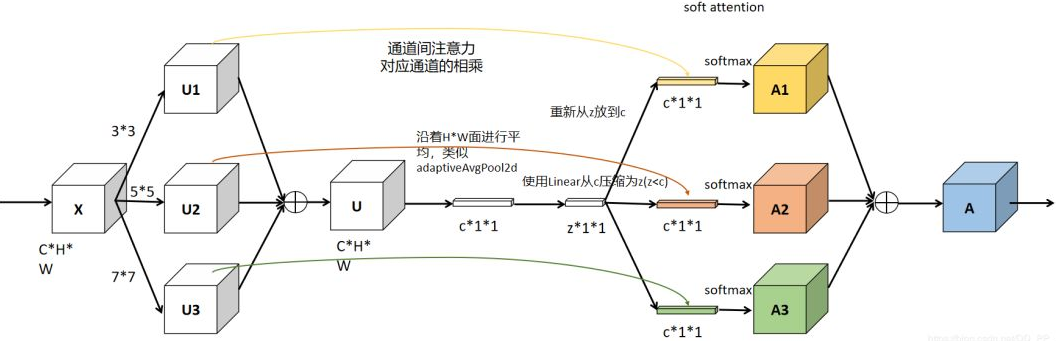
网络主要由 Split、Fuse、Select 三部分组成。
Split 部分 是对原特征图经过 不同大小的卷积核 部分进行卷积的过程,这里可以有多个分支。
对输入X使用不同大小卷积核分别进行卷积操作 (图中的卷积核 size 分别为 3×3 和 5×5 两个分支,但是可以有多个分支)。操作包括卷积、efficient grouped / depth-wise convolutions、BN。
Fuse 部分 是 计算每个卷积核权重 的部分。
将两部分的特征图按元素求和
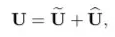
U 通过全局平均池化(GAP)生成通道统计信息。得到的 Sc 维度为 C×1
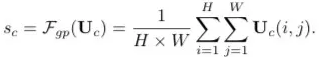
经过全连接生成紧凑的特征 z(维度为 d×1), δ 是 RELU 激活函数,B 表示批标准化(BN),z 的维度为卷积核的个数,W 维度为 d×C, d 代表全连接后的特征维度,L 在文中的值为 32,r 为压缩因子。
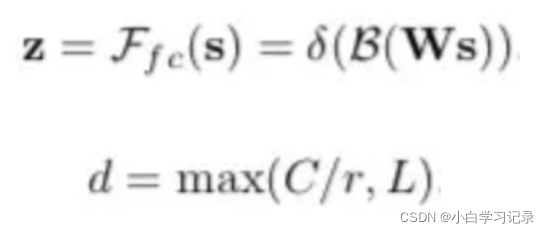
Select 部分 是根据不同权重卷积核计算后 得到的新的特征图 的过程。
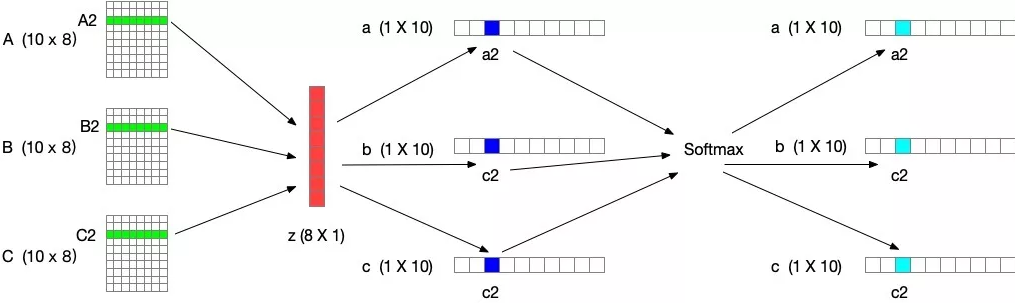
进行 Softmax 计算每个卷积核的权重,计算方式如下图所示。如果是两个卷积核,则 ac + bc = 1。z的维度为(d×1)A的维度为(C×d),B的维度为(C×d),则 a = A×z 的维度为1×C。
Ac、Bc 为 A、B 的第 c 行数据(1×d)。ac 为 a 的第 c 个元素,这样分别得到了每个卷积核的权重。

将权重应用到特征图上。其中 V = [V1,V2,…,VC],Vc 维度为(H×W),如果

select 中 Softmax 部分可参考下图(3个卷积核)
二、代码部分
import torch
import torch.nn as nn
class SKConv(nn.Module):
def __init__(self, in_channels,out_channels , M=2, G=32, r=16, stride=1, L=32):
""" Constructor
:param in_channels: 输入通道维度
:param out_channels: 输出通道维度 原论文中 输入输出通道维度相同
:param stride: 步长,默认为1
:param M: 分支数
:param r: 特征Z的长度,计算其维度d 时所需的比率(论文中 特征S->Z 是降维,故需要规定 降维的下界)
:param L: 论文中规定特征Z的下界,默认为32
:param G: 分组卷积G=32
"""
super(SKConv, self).__init__()
d = max(int(in_channels// r), L) # 计算向量Z 的长度d
self.M = M
self.out_channels = out_channels
self.convs = nn.ModuleList([]) # 根据分支数量 添加 不同核的卷积操作
for i in range(M):
# 为提高效率,原论文中 扩张卷积5x5为 (3X3,dilation=2)来代替。且论文中建议分组卷积G=32
self.convs.append(nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1 + i, dilation=1 + i, groups=G,
bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=False)
))
# 自适应 pool 到指定维度 - GAP
self.gap = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Sequential(nn.Conv2d(out_channels, d, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(d),
nn.ReLU(inplace=False)) # 降维
self.fcs = nn.ModuleList([])
for i in range(M):
self.fcs.append(
nn.Conv2d(d, out_channels, kernel_size=1, stride=1) # 升维
)
self.softmax = nn.Softmax(dim=1) # 指定 dim=1 令两个 FCs 对应位置进行 softmax,保证 对应位置a+b+..=
def forward(self, x):
batch_size = x.shape[0]
#the part of split
feats = [conv(x) for conv in self.convs]
feats = torch.cat(feats, dim=1)
feats = feats.view(batch_size, self.M, self.out_channels, feats.shape[2], feats.shape[3])
#the part of fusion
feats_U = torch.sum(feats, dim=1) # 逐元素相加生成 混合特征
feats_S = self.gap(feats_U)
feats_Z = self.fc(feats_S) #降维
#the part of Select
attention_vectors = [fc(feats_Z) for fc in self.fcs]
attention_vectors = torch.cat(attention_vectors, dim=1)# 升维度
attention_vectors = attention_vectors.view(batch_size, self.M, self.out_channels, 1, 1)
attention_vectors = self.softmax(attention_vectors)
feats_V = torch.sum(feats * attention_vectors, dim=1)
return feats_V
if __name__ == "__main__":
t = torch.ones((32, 256, 24, 24))
sk = SKConv(256,256)
out = sk(t)
print(out.shape)
